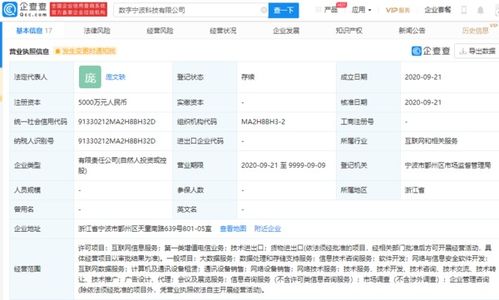
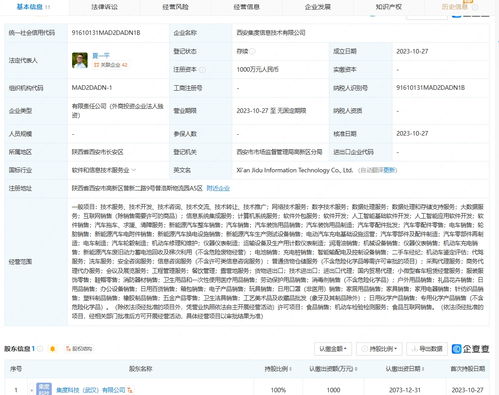
字節跳動 EB 級 Iceberg 數據湖 機器學習應用、優化與數據服務支撐體系
在數據驅動的時代,擁有海量數據并進行高效、智能的處理與分析,已成為科技巨頭的核心競爭力。字節跳動,作為全球領先的內容與信息平臺,其龐大的業務生態每日產生海量數據。為應對這一挑戰,字節跳動構建并深度應用了 EB 級的 Apache Iceberg 數據湖架構,不僅為上層機器學習應用提供了堅實的數據基石,更在數據處理效率、存儲成本優化及服務化支撐方面取得了顯著成果。
一、Iceberg 數據湖:機器學習的數據基石
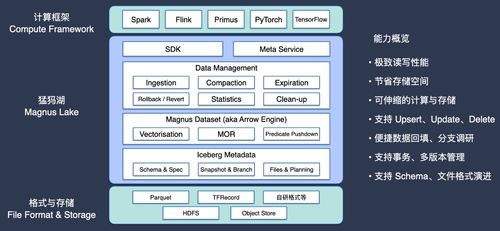
Apache Iceberg 作為一種開源的高性能表格式,解決了傳統數據湖(如直接基于 HDFS)在數據一致性、 schema 演進、事務支持及高效查詢上的諸多痛點。字節跳動將其作為核心數據湖表格式,構建了覆蓋推薦、廣告、搜索、內容安全等核心業務的統一數據底座。
對于機器學習而言,這一數據基石至關重要:
- 訓練數據管理:機器學習模型的訓練依賴于高質量、大規模的歷史特征數據。Iceberg 的 ACID 事務保證確保了訓練數據的一致性視圖,避免了因數據更新而產生的“臟讀”問題。其精細化的分區策略與隱式分區功能,使得數據工程師和算法工程師能夠高效地定位和讀取特定時間范圍、特定用戶群體或特定內容類型的訓練樣本。
- 特征工程與存儲:特征倉庫是機器學習系統的核心組件。利用 Iceberg 的 Schema 演進能力,可以安全、靈活地添加、刪除或修改特征列,而無需重寫整個歷史數據表,這極大地支持了特征迭代與實驗的敏捷性。Iceberg 對 Parquet、ORC 等高效列式存儲格式的深度支持,使得特征數據的讀取能夠“按需取列”,大幅減少了 I/O 開銷,加速了特征抽取流程。
- 線上/線下數據一致性:通過 Iceberg 管理的特征表,可以作為線下訓練和線上推理共享的唯一數據源,確保了特征計算邏輯的一致性,有效規避了“訓練-服務偏差”,提升了模型上線后的穩定性和效果。
二、核心優化實踐:性能、成本與效率
面對 EB 級的數據規模,字節跳動對 Iceberg 數據湖進行了一系列深度優化:
- 數據布局優化:
- 智能分區與排序:結合業務查詢模式(如頻繁按天、按用戶查詢),設計高效的分區策略。在數據寫入時引入 Z-Order 等多維排序技術,將相關聯的數據(如同用戶 ID 的行為記錄)在物理上聚集存儲,顯著提升了查詢性能,減少了掃描數據量。
- 小文件合并:流式數據持續寫入極易產生海量小文件,嚴重拖累查詢性能。字節跳動實現了自動化的后臺小文件合并任務,根據文件大小、數量等閾值觸發合并操作,保持數據湖的“健康度”。
- 查詢加速與索引:
- 利用 Iceberg 的元數據(如 Manifest 文件)進行高效的剪枝,快速跳過不相關的數據分區和文件。
- 探索并集成布隆過濾器等二級索引,在文件級別進一步過濾無關數據行,為點查和特征回填等高并發查詢場景提供支持。
- 存儲成本管控:
- 數據生命周期管理 (DLM):自動化識別冷、熱、溫數據,并結合分層存儲策略(如熱數據存于高性能 SSD/內存,溫數據存于標準 HDD,冷數據歸檔至對象存儲)。Iceberg 的表格式抽象使得在不同存儲介質間遷移數據對上層應用透明。
- 數據壓縮與編碼優化:針對不同類型的特征數據(如稀疏向量、枚舉值),采用最合適的壓縮算法和編碼方式,在保證查詢性能的同時最大化節約存儲空間。
三、數據處理與存儲支持服務:平臺化與自助化
為使業務和算法團隊能夠高效、便捷地利用這一龐大的數據湖,字節跳動構建了強大的數據處理與存儲支持服務體系:
- 統一數據服務平臺:提供了從數據接入、ETL 開發、任務調度、質量監控到數據目錄(Data Catalog)的一站式服務。用戶可以通過 SQL 或可視化界面輕松地創建、管理 Iceberg 表,查詢數據血緣,并訂閱數據質量報告。
- 高性能查詢引擎集成:數據湖的價值在于被高效查詢。字節跳動將 Iceberg 與 Presto/Trino、Spark、Flink 以及內部自研的查詢引擎深度集成,為不同的計算場景(即席分析、批處理、流批一體)提供統一的入口和最優的執行性能。
- 機器學習特征平臺:基于 Iceberg 數據湖,構建了特征平臺,提供特征定義、計算、存儲、上線和監控的全鏈路能力。算法工程師可以自助完成特征注冊、回溯計算、生成訓練樣本集,并將特征表一鍵發布為線上推理服務可訪問的存儲視圖。
- 可觀測性與治理:提供了全面的監控大盤,涵蓋數據湖的存儲量增長、文件分布、查詢熱度、任務耗時、成本消耗等維度。結合智能告警,幫助運維和開發團隊快速發現和解決問題。通過數據治理工具管理元數據質量、數據安全與權限,確保數據湖的合規、有序運行。
###
字節跳動 EB 級 Iceberg 數據湖的實踐表明,一個設計優良、深度優化的數據湖架構,是規模化機器學習應用取得成功的關鍵基礎設施。它不僅解決了海量數據的存儲與管理問題,更通過性能優化與成本管控,以及全面的平臺化服務支持,將數據高效、可靠、經濟地轉化為機器學習模型的生產力,持續驅動著字節跳動各項業務的智能進化與創新。隨著實時機器學習、大模型訓練等場景的深入,對數據湖的實時性、吞吐量和跨域協同能力將提出更高要求,Iceberg 及其生態的持續演進值得期待。
如若轉載,請注明出處:http://www.jiyidai.cn/product/15.html
更新時間:2026-05-30 07:37:53